[RN/AI] Pytorch로 AI 모델을 학습시켜 모바일 앱에 적용하기
앱을 만들다보면 자연스레 AI 기술에 관심을 가지게 된다.
“요즘 chatGPT가 그렇게 핫하다는데 나도 AI 좀 접목시켜 볼까…?” 라는 상상을 하게 된다
그렇다면 어떻게 해야할까? 하나하나 차근차근 파헤쳐보자.

위 영상은 카메라에 비친 물체 중에서 강아지의 코를 인식하는 영상이다. 이는 Object Detection이라는 기술을 활용하고 있다.
Object Detection에 대한 설명은 다음과 같다.
이미지나 비디오에서 사람, 자동차, 동물, 가방 등과 같은 특정 객체를 식별하고, 이 객체들의 위치를 정확히 찾아내는 기술. 대표적인 모델로는 YOLO, SSD, Faster R-CNN 등이 있고 자율 주행, 보안 및 감시, 영상 분석 등에 활용된다.
※ 혹시 chatGPT와 같은 NLP(자연언어처리)를 생각하고 왔는데 실망하신 분이 있을지도 모르겠다. 하지만 딥러닝 기술은 CV가 되었든 NLP가 되었든 기본적인 원리에서는 큰 차이가 없다. 과거에는 방법론적인 차이가 분명이 존재했지만 현재 두 분야는 그러한 경계선조차 점점 허물어지고 있다. 따라서 어느쪽을 익혀두면 나머지를 응용하는 것은 꽤나 쉽다. 고로 둘 다 해보는 것을 추천한다.
이번 글에서는 Object Detection을 활용한 강아지 코 인식 모델을 React Native 앱에 적용해볼 것이다.
🍀 프로세스
전체적인 흐름은 다음과 같다.

1. 데이터 라벨링
AI 모델을 훈련시키기 위해서는 그에 적합한 데이터가 필요하다.
오픈소스 데이터를 활용하는 것이 가장 좋지만, 원하는 데이터가 없다면 직접 만들 수밖에 없다.
여기서는 labelImg라는 라벨러를 사용하여 데이터를 직접 만들어볼 것이다.
(이 과정이 정 귀찮다면 파인튜닝된 모델을 깃허브, 허깅페이스 같은 곳에서 받아와서 사용해도 좋다.)
2. 데이터 전처리
모델을 학습시키는 데이터의 형식에는 여러가지가 있지만 우리가 만들 모델은 csv를 필요로 하기에 xml 형태의 데이터를 csv로 변환할 것이다.
실전에서는 원하는 모델의 형식에 맞게 데이터셋을 변형해보자.
3. 모델 훈련
만들어 놓은 데이터셋으로 모델을 학습시켜본다.
GPU가 있으면 더 빠르고 좋지만, CPU로도 나름 괜찮은 모델을 학습할 수 있다.
우리는 도커를 통해 딥러닝용 가상환경 위에서 학습을 진행할 것이다.
4. 모델 테스트
의도한대로 잘 학습이 진행되었는지, 정확도는 얼마인지, 실제로 잘 작동하는지 확인한다.
더불어 라이브 테스트도 진행해보자.
5. 모델 변형
우리가 훈련시킨 모델을 모바일 앱에서 사용하기 위해서는 특정 형식이 필요하다.
모델 파일 형식이 .pth로 되어있을텐데, 이를 .ptl파일로 변경해주어야 한다.
이 과정에서 torch.jit을 통한 모델 튜닝에 관한 이야기를 할 것이다.
6. 모델 적용
해당 모델을 실제로 React Native 프로젝트에도 적용해보자.
결과물을 보고 모델 최적화에 대해서도 고민해보자.
🏷️ 데이터 라벨링 (Data Labeling)
모델 학습에 필요한 데이터를 만들기 위해서는 원본(raw) 데이터와 라벨링 툴이 필요하다. (*Object Detection에 필요한 데이터는 원본 이미지와 바운딩 박스에 관한 좌표 정보이다.)
먼저 원본 데이터부터 준비하자.
원본 데이터는 Stanford Dogs Dataset을 사용할 것이다. 120종의 강아지 사진 총 20,580장이 모여있는 데이터셋이다.
모든 이미지를 사용할 필요는 없고, 원하는만큼 이미지를 특정 폴더로 옮겨준다. (모델 성능이 잘 안나올 경우 나중에 더 많은 데이터를 가져오면 되므로 일단은 조금만 옮겨보자. 물론 층화 샘플링(Stratified Sampling)을 해주면 가장 좋다.)
해당 폴더는 이제 새로운 데이터셋 폴더로 사용될 것이다.
기본 데이터가 준비되었다면 이제 labelImg라는 툴을 소개하고자 한다. 간단히 설명하자면 다음과 같다.
Object Detection 모델 학습에 필요한 주석(Annotation) 처리된 이미지를 생성할 수 있게 도와주는 도구이다.
깃허브 페이지에 들어가보면 설치 및 사용 방법에 대해 상세히 설명하고 있다.
단, 필자는 M1 Pro chip MacBook Pro 14를 사용하고 있는데 설치 가이드에 부족한 내용이 있어 관련 내용을 추가한다.
⚠️ pyrcc5: No such file or directory 혹 이러한 에러를 만난다면 아래 코드대로 설치한다.
brew install qt qt@5
brew install libxml2
brew install pyqt@5
pip3 install pyqt5 lxml
git clone https://github.com/HumanSignal/labelImg.git
cd labelImg
make qt5py3
python3 labelImg.py실행 화면은 아래와 같다.
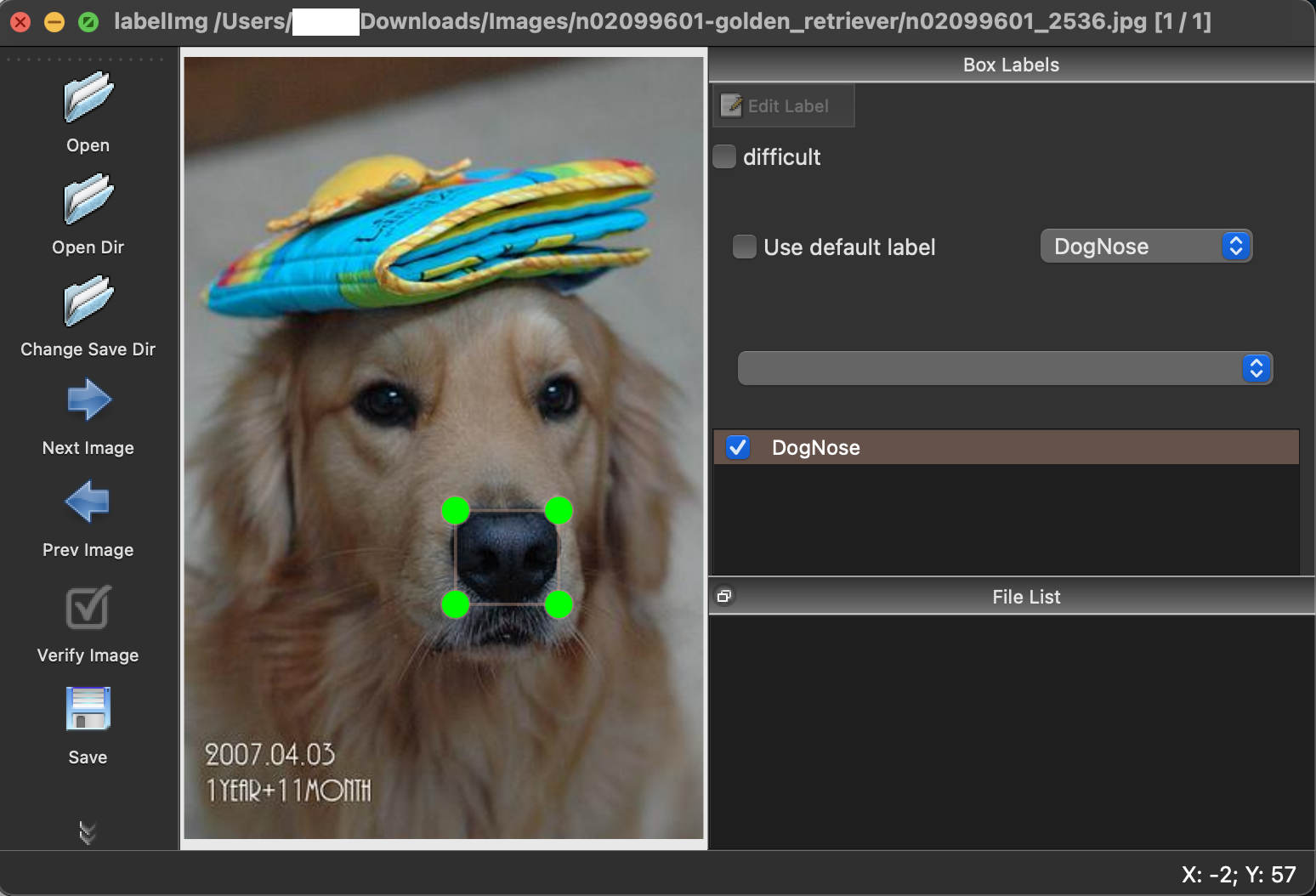
labelImg/data 폴더 안에 predefined_classes.txt라는 파일이 있는데 이 안에는 분류하고 싶은 클래스명을 적어주면 된다.
조작 순서는 이미지 불러오기 -> 바운딩 박스 생성 -> 저장하기 순이다. 사용법이 직관적이므로 매우 쉽다.
단축키는 주로 이렇게 세 가지를 사용하면 된다.
| 키 | 설명 |
|---|---|
| w | 박스 생성 |
| d | 다음 이미지 |
| a | 이전 이미지 |
사진 위에 바운딩 박스를 만들고 저장을 누르면 해당 정보가 xml 파일로 저장되는 것을 볼 수 있는데, 우선 한 폴더에 이미지 파일과 메타데이터 파일(xml)을 모아놓자.
🔖 데이터 전처리
우리가 사용할 모델은 Object Detection에서 유명한 SSD이다. SSD 모델 구현에 있어서는 여기를 참고하였다.
해당 모델을 사용하기 위해서는 위에서 라벨링한 데이터를 모델에 맞게 변형할 필요가 있다.
필수 요소는 이미지 폴더와 그와 관련한 바운딩 박스 정보를 담고 있는 csv 파일이다.
위에서 만든 데이터셋 폴더(이미지+메타데이터)에 xml_to_csv.py(url 첨부) 파일을 넣고 실행시켜준다.
python3 xml_to_csv.py다음과 같이 정리될 것이다.
🗂️ label
sub-test-annotations-bbox.csv
sub-train-annotations-bbox.csv
sub-validation-annotations-bbox.csv
🗂️ test
🗂️ train
🗂️ validation이제 모델에 넣을 데이터가 준비되었다. 앞으로 이 데이터셋을 dognose_dataset이라고 부를 것이다.
🧭 모델 훈련
드디어 모델을 학습시켜볼 차례이다. 모델 학습에는 다음 네 가지가 필요하다.
1️⃣ 사전 학습 모델
2️⃣ 코드
3️⃣ 데이터
4️⃣ 개발 환경
이제 이것들을 하나씩 모아볼 것이다.
먼저 우리가 사용할 모델(코드) pytorch-ssd를 받아오자.
git clone https://github.com/qfgaohao/pytorch-ssd.git
cd pytorch-ssd해당 코드에서 우리의 데이터를 사용할 수 있도록 data 폴더를 만들어서 그 안에 dognose_dataset을 넣어준다.
딥러닝에서 중요한 개념 중 하나가 전이 학습인데, 기존에 잘 학습된 모델이 있다면 그 모델을 가져와서 추가 학습을 시키는 것이 학습 속도를 크게 단축시키는 하나의 방법으로 알려져있다.
pytorch-ssd에서 PASCAL VOC 데이터셋에 대해 미리 학습시켜놓은 모델을 제공하고 있으므로 이를 활용할 것이다.
깃허브 페이지에 다운로드 URL이 있으므로 원하는 모델을 다운로드 하면 된다. 필자의 경우 mb2-ssd-lite-mp-0_686.pth를 다운로드 하였다. 다운로드를 하였다면 models 폴더 안에 넣어주면 된다.
사실 사전 학습 모델을 직접 만들어도 좋고, 그냥 베이스 모델을 가지고 우리의 데이터셋을 학습시키는 것도 좋다. 모든 방법을 시도해서(시간이 오래걸리지 않는다면) 가장 좋은 모델을 만들어내는 것이 우리의 목표이기 때문이다.
코드, 사전학습 모델, 데이터. 재료는 다 모은 것 같으므로 이제는 코드를 돌릴 일만 남았다. 하지만 코드를 돌리려면 해당 코드에서 필요로 하는 패키지들을 전부 다운받아야 한다. 문제는 딥러닝을 사용하기 위해서는 정말 많은 라이브러리가 필요하다는 것이다.
많은 개발자들이 anaconda와 같은 파이썬 배포판을 사용하여 개발 환경을 구축하고 있지만 각종 패키지 간의 호환성을 유지하는 것은 여간 수고가 많이 드는 일이 아니다. 만약 딥러닝 개발환경이 미리 구축되어 있는 환경이 있다면 어떨까?
고맙게도 도커를 사용한다면 이미 많은 사람들이 구축해놓은 개발 환경을 이용할 수 있다. 즉, 복잡한 환경 설정에 신경 쓸 필요없이 모델 학습에만 집중할 수 있다는 얘기다. (물론 개인만의 개발환경을 구축하고 싶다면 직접 구축하는 것이 훨씬 좋다.)
자, 그러면 deepo라는 유명한 도커 이미지를 사용하여 개발 환경을 구축해보자.
Deepo is an open framework to assemble specialized docker images for deep learning research without pain.
이번 장에서는 CPU를 통한 학습을 기준으로 한다. 로컬에 있는 코드와 사전 학습 모델, 데이터를 전부 활용해야 하므로 현재 위치가 컨테이너 안에 마운트되도록 설정한다. (pytorch-ssd 폴더 안에서 실행해야 한다는 이야기)
docker pull ufoym/deepo:cpu # CPU 전용 이미지 다운로드
docker run -it --shm-size 8G -v "$(pwd)":/mount ufoym/deepo:cpu bash여기서 —shm-size 8G 옵션을 넣어주지 않으면 학습시 다음과 같은 에러를 만나게 되므로 주의하자.
RuntimeError: DataLoader worker (pid 938) is killed by signal: Bus error. It is possible that dataloader’s workers are out of shared memory. Please try to raise your shared memory limit.
이는 데이터로더에 너무 많은 데이터 용량이 올라갔기 때문이다. 메모리 제한을 올려주면 간단히 해결된다.
만약 GPU를 사용하고 싶다면 GPU 전용 도커 이미지와 nvidia-docker2를 활용하면 된다. 아래는 그 예시이다.
# nvidia-docker2가 설치되었다고 가정
docker pull ufoym/deepo # GPU 전용 이미지 다운로드
docker run -it --gpus all --shm-size 8G -v "$(pwd)":/mount ufoym/deepo bashNvidia GPU가 있다면 무조건 활용하는 것이 좋다. CPU와 엄청난 연산 속도 차이를 보이기 때문이다.
pytorch-ssd를 돌릴 때 추가로 설치해 주어야하는 패키지가 있어서 도커 환경에 접속했다면 아래 패키지를 설치해준다.
# ModuleNotFoundError: No module named 'cv2’
pip install opencv-python
# ImportError: libGL.so.1: cannot open shared object file: No such file or directory
apt-get update
apt-get install libgl1-mesa-glx혹여나 exit으로 컨테이너를 빠져나온 뒤에 재접속 하고 싶다면 이렇게 하면 된다.
sudo docker start 컨테이너ID
sudo docker attach 컨테이너ID이제 정말 모든 준비를 마쳤다. pytorch-ssd 페이지를 참고해서 모델 학습을 시작해보자. mount 폴더로 이동하여 아래 명령어를 입력한다.
python train_ssd.py --dataset_type open_images --datasets /mount/data/dognose_dataset --net mb2-ssd-lite --pretrained_ssd models/mb2-ssd-lite-mp-0_686.pth --scheduler cosine --lr 0.01 --t_max 100 --validation_epochs 10 --num_epochs 100 --base_net_lr 0.001 --batch_size 8 --debug_steps 10딥러닝을 접한지 얼마 안 된 분들이라면 뒤에 붙은 수많은 옵션에 놀라셨을지 모른다. 이는 딥러닝에서 꽤나 중요하게 작용하는 하이퍼파라미터의 집합이며, 개발자는 이러한 값을 바꿔가며 가능한 모든 시나리오의 조합을 확인한 뒤 가장 좋은 모델을 생성하는 하이퍼파라미터를 찾아낸다. 그렇기에 한번에 최상의 모델이 뚝딱 탄생하는 것은 아니며, 본인이 선택한 파라미터에 따라 모델의 성능은 뒤바뀔 수 있다는 사실을 염두에 두어야한다.
※ 아마 위의 명령어는 원본 코드에서 에러를 발생시킬 것인데, 이것은 모델에 들어가는 데이터의 양식을 필자가 살짝 건드렸기 때문이다. 모든 이미지가 jpg형식으로 주어지지는 않을 것이라 생각하여 이미지 압축 형식에 영향을 받지 않도록 하였다.
⚠️ AttributeError: 'NoneType' object has no attribute 'shape'
# /vision/datasets/open_images.py 의 _read_image 함수 수정
🔑 image_file = self.root / self.dataset_type / f"{image_id}" # <- .jpg 삭제※ 만약 훈련 데이터셋의 길이가 배치 사이즈로 딱 나누어 떨어지지 않는다면 다음과 같은 에러가 발생한다.
⚠️ raise ValueError("Expected more than 1 value per channel when training, got input size {}".format(size))
🔑 train_ssd.py 에서 DataLoader 안에 drop_last=True 조건을 추가해준다.정상적으로 훈련이 진행된다면, 데이터셋에 대한 정보가 먼저 나열된 뒤 다음과 같이 Epoch 0부터 모델이 학습을 시작한다.

MacBook Pro 2021년 모델 기준, CPU로 학습시 1 epoch 당 대략 3분 30초 정도 소요되었다. 100 epoch를 전부 학습하는데는 약 9시간 정도가 소요되었다. 물론 GPU로 학습시에는 속도가 비약적으로 빨라질 것으로 예상된다. (훈련 데이터셋은 약 700장이다)
너무 오래걸린다 생각이 되면 10 epoch마다 모델의 check point를 저장해주므로 적당한 loss가 나왔을 때 중지시켜도 된다.
학습이 끝난 뒤 models 폴더를 보면 mb2-ssd-lite-Epoch-?-Loss-?.pth 형태의 파일이 저장되는데 이것이 바로 우리가 사용할 모델이다.
☑️ 모델 테스트
모델이 제대로 학습되었는지, 제대로 예측을 하고 있는지 테스트를 해 볼 시간이다.
우선 한 장의 이미지(dog.jpg)를 넣어서 강아지의 코를 잘 찾는지 보자. (pytorch-ssd 폴더 안에 원하는 이미지를 넣는다)
당연한 이야기지만 도커 환경 위에서 실행해야 한다.
python3 run_ssd_example.py mb2-ssd-lite models/mb2-ssd-lite-Epoch-?-Loss-?.pth models/open-images-model-labels.txt dog.jpgopen-images-model-labels.txt는 자동 생성되는 파일이지만 DogNose라벨을 포함하는지 확인하자.
예측이 끝나면 run_ssd_example_output.jpg라는 이름의 결과 이미지 파일이 생성될 것이다.
아래는 테스트 결과이다.

98%의 확률로 강아지 코를 예측하고 있는 것을 알 수 있다. 나쁘지 않다.
간혹 run_ssd_example.py 파일에서 에러가 나는 경우가 있다. 아래와 같이 해결하자.
⚠️ cv2.error: OpenCV(4.10.0) :-1: error: (-5:Bad argument) in function 'rectangle'
🔑 type 에러이므로 box[?] 요소를 전부 정수 변환 해준다 -> int(box[?])또한, 우리가 만든 테스트 데이터셋에 대해서 정확도를 측정하는 것도 가능하다.
python eval_ssd.py --dataset_type open_images --net mb2-ssd-lite --dataset /mount/data/dognose_dataset --trained_model models/mb2-ssd-lite-Epoch-?-Loss-?.pth --label_file models/open-images-model-labels.txt위 명령어를 실행하면 모델이 테스트 데이터셋을 돌면서 예측을 진행하고 마지막에 전체 정확도를 계산해준다.
Average Precision Per-class:
DogNose: 0.8976893924291722
Average Precision Across All Classes:0.8976893924291722약 90%의 정확도가 나왔다. 이정도면 나쁘지 않다.
그렇다면 Live로도 잘 판단해줄까? 아래 명령어로 직접 확인해보자.
카메라 권한이 필요하기에 도커보다는 로컬에서 진행하기를 추천한다. torch, torchvision, opencv-python 만 다운로드하면 문제없이 코드를 돌릴 수 있다.
pip3 install torch torchvision opencv-python
python3 run_ssd_live_demo.py mb2-ssd-lite models/mb2-ssd-lite-Epoch-?-Loss-?.pth models/open-images-model-labels.txt카메라가 실행되면 실제 강아지나 사진을 비춰서 모델이 코를 제대로 인식하나 살펴보자.
여기까지 잘 따라왔다면 이젠 PC에서 딥러닝을 돌릴 줄 아는 것이다. 축하한다.
🛤️ 모델 변환
우리가 앞에서 얻은 모델을 앱에 내장하기 위해서는 .pth로 되어있는 파일 형식을 .ptl로 바꿔주어야 한다.
PlayTorch 공식문서에 나와있는 코드를 조금 수정하여 모델 변환 코드를 작성하였다.
# export_model.py
import torch
from torch.utils.mobile_optimizer import optimize_for_mobile
from vision.ssd.mobilenet_v2_ssd_lite import create_mobilenetv2_ssd_lite, create_mobilenetv2_ssd_lite_predictor
model = create_mobilenetv2_ssd_lite(2, is_test=True)
model_path = 'models/mb2-ssd-lite-Epoch-?-Loss-?.pth'
model.load(model_path)
model.eval()
scripted_model = torch.jit.script(model)
optimized_model = optimize_for_mobile(scripted_model)
optimized_model._save_for_lite_interpreter("models/mb2-ssd-lite-Epoch-?-Loss-?.ptl")
print("model successfully exported").ptl 파일을 얻기 위해서는 먼저 torch.jit을 사용하여 모델을 Eager mode에서 Script mode로 변환해주어야 한다. 변환 방법에는 torch.jit.trace와 torch.jit.script 이렇게 두 가지 방식이 있는데 여기서는 script를 사용하였다.
trace 방식은 모델 변환시 성공률은 높지만 제대로된 변환을 보장해주지는 않는다. 반면 script 방식은 모델 구조에 꽤나 엄격하기에 제대로 된 형태가 아닐 경우 에러를 내뿜을 가능성이 높다. 가능하다면 둘 다 시도하여 모델 성능을 비교해보자.
아래는 script방식에서 자주 마주치는 에러이다. 동적 인덱싱을 사용할 수 없기 때문에 enumerate 함수로 iterator를 사용하여 해결하거나 integer를 직접 넣어 인덱싱 하는 수밖에 없다.
⚠️ ModuleList/Sequential indexing is only supported with integer literals.
변환을 위해 /vision/ssd/ssd.py의 forward 함수를 수정해주었다. 가독성을 조금 해치지만 enumerate를 사용하기 애매한 부분은 for 문을 풀어서 작성하였다.
아래 명령어로 변환을 하였을 때 model successfully exported라는 말이 나온다면 성공이다.
python3 export_model.py🍿 모델 적용
Snack에서 간단한 코드를 작성한 뒤 Playtorch 앱에서 실행시켜볼 계획이었으나 PlayTorch 프로젝트가 사실상 잠정 중단되었기에 이제 이 방법은 불가능하다.
This project has been archived and is no longer actively maintained.
일반적인 앱은 PlayTorch 대신 Expo Go에서 돌려볼 수 있으나 react-native-pytorch-core 라이브러리와의 호환성 문제가 존재하므로 우리의 목적과는 거리가 있다.
따라서 새로운 React Native 프로젝트를 만들어서 테스트 해보는 것이 합리적이다.
준비물은 다음과 같다.
App.js
predictor.js
metro.config.js
mb2-ssd-lite-Epoch-?-Loss-?.ptl
ImageNetClasses.jsonApp.js와 predictor.js는 react-native-pytorch-core를 이용하여 React Native 안에서 Tensor를 조작하거나 카메라를 사용하는 컴포넌트를 담고 있다. 이는 PlayTorch의 예제들을 살펴보면 쉽게 알 수 있으므로 설명은 생략하겠다.
중요한 것은 우리가 만든 .ptl 파일을 React Native가 인식하지 못한다는 것인데 이는 metro.config.js에서 관련 설정을 해주면 된다.
const { getDefaultConfig, mergeConfig } = require("@react-native/metro-config");
/**
* Metro configuration
* https://reactnative.dev/docs/metro
*
* @type {import('metro-config').MetroConfig}
*/
const defaultConfig = getDefaultConfig(__dirname);
const defaultAssetExts =
require("metro-config/src/defaults/defaults").assetExts;
const config = {
resolver: {
assetExts: [...defaultAssetExts, "ptl"],
},
};
module.exports = mergeConfig(defaultConfig, config);설정이 바뀌었으니 이제 metro를 재시작해준다.
npm start --reset-cache혹시나 적용하는 앱에 카메라 접근 권한 설정이 되어있지 않다면 info.plist에서 관련 권한을 추가해주어야 한다.
결론
이제 모든 과정이 끝났다.
아무래도 핸드폰이라는 제약된 하드웨어 환경에서 딥러닝을 돌리다보니 성능 이슈가 존재할 수 있다. (발열, 끊김 등)
개선의 여지는 있겠지만 아무래도 카메라를 이용하는 Computer Vision 쪽에서는 발열 이슈를 피할 수 없을 것이라 생각한다.
그래도 RAM은 150MB 언저리로 사용하는 것을 보니 엄청난 성능을 필요로 하지는 않는 듯하다.

테스트를 해보니 강아지 모형에 대해서는 20%의 확률로 강아지 코라고 인식하고 있었다.😶
실제 강아지를 대상으로 테스트할 경우 정확도가 더 올라갈 수 있다. 다만, 얌전한 강아지를 찾기 힘들다는 문제가 있다.
코드는 https://github.com/froggydisk/mobileAI에서 볼 수 있으므로 참고를 원하시는 분들은 마음껏 테스트 해보셔도 좋다.